Introduction
If you train machine learning models, then you know the challenge of going from experiment to production. There's a vast range of tools that promise to help, from experiment tracking through to model deployment, but setting these up requires a lot of time and cloud engineering knowledge.
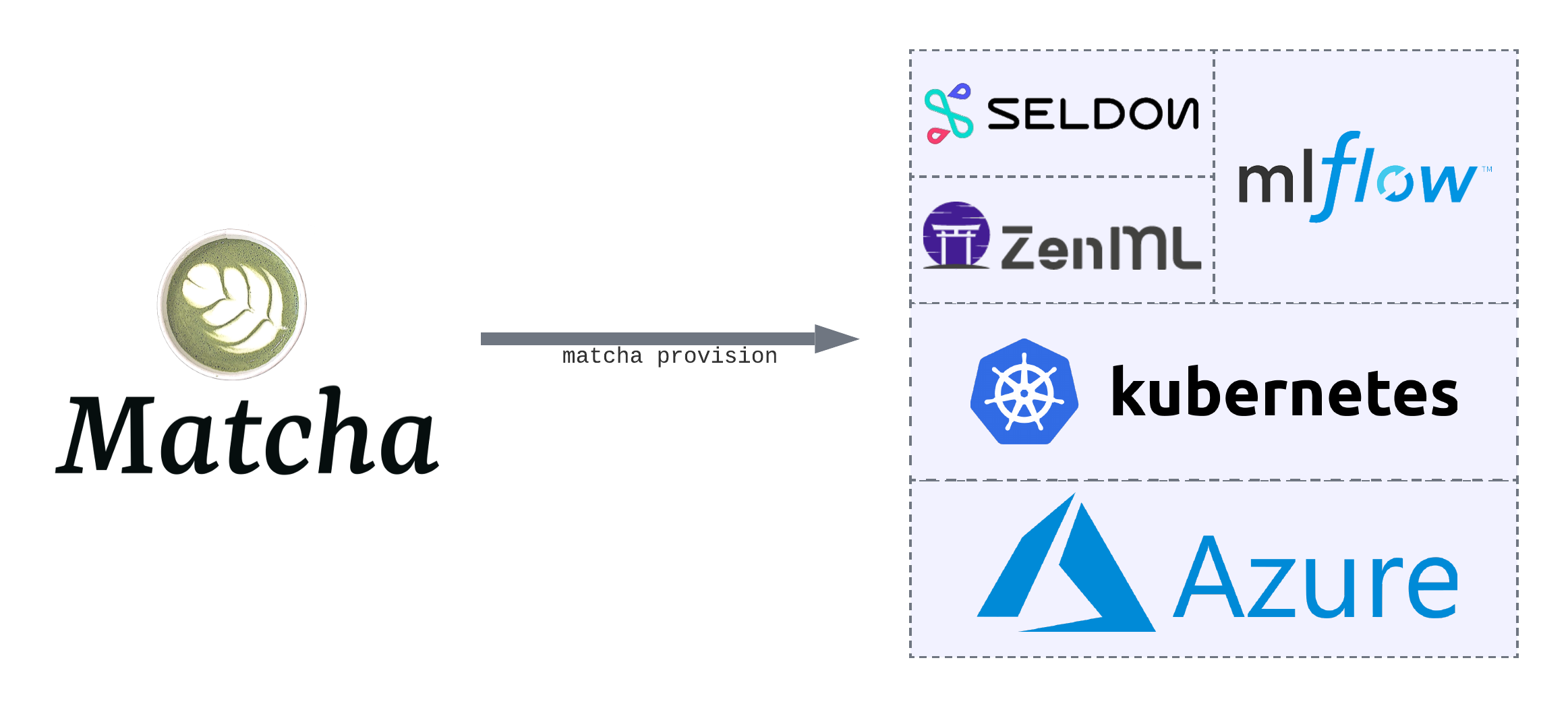
Matcha removes the complexity of provisioning your machine learning infrastructure. With one step, you'll have a complete machine learning operations (MLOps) stack up and running in your Microsoft® Azure cloud environment. This means you'll be able to track your experiments, train your models, as well as deploy and serve those models.

Under the hood, Matcha leverages a number of other open source tools: we use MLFlow to track experiments, Seldon to serve models, ZenML for orchestration, and Kubernetes for model training workloads, as well as for hosting everything else. Matcha's job is to bring together the best MLOps tooling, and set them up for you, so you can focus on training models.
Along with setting up your infrastructure, Matcha comes with a set of well-engineered examples, covering common machine learning use-cases. These examples will help you make the most out of Matcha.
Who is Matcha for?
Matcha is for data scientists, machine learning engineers, and anybody who trains machine learning models. If you're using Azure, and want an intuitive way to deploy machine learning infrastructure, Matcha is for you.
How do I get started?
If you're new to Matcha, the best place to start is our guide to deploying your first model.
If you're happy with the basics, then you might want to dive into our Matcha examples on Github. More advanced users may be interested in learning how Matcha works inside.
Why use Matcha?
These days there are lots of MLOps platforms and tools to choose from, and you might wonder what's different about Matcha.
To begin with, it's important to say that Matcha isn't a platform, so it's not directly comparable to something like the Azure Machine Learning Platform, or Amazon Sagemaker. Platforms try to offer an all-in-one solution, but we see two problems with platforms: firstly, you're locked in to a particular vendor, and secondly they suffer from being a jack of all trades, master of none.
Open source is the solution. In designing Matcha, we've hand-picked existing tools that each do one thing well. Matcha's job is to deploy and manage those tools on your behalf, but there's nothing proprietary in how we do that, so you'll never be locked in.
The Matcha roadmap
We've put a lot of thought into what our users — data scientists, ML engineers, etc — need from their infrastructure, and we came up with 5 key pieces of functionality that are absolute musts:
- A place to track, version, and manage datasets.
- A place to track experiments and models assets.
- Scalable compute for running training workloads, with the option to use GPUs.
- Somewhere to deploy and serve models in a way that scales with your application needs.
- The ability to monitor models for things like drift and bias.
Matcha is still in alpha release, and we don't support everything on that list yet. We support experiment tracking, training, and deployment, with plans to add data versioning and monitoring later. We very much welcome input on our roadmap from our early users.
Who maintains Matcha?
Matcha is an open source project maintained by Fuzzy Labs, and released under the Apache 2.0 license. The greatest strength of open source is community, and we encourage our users to contribute back to the project through ideas, pull requests, and bug reports. To help out, see out guide for contributors.
Note: Matcha is still in alpha release. While we've worked hard to ensure there are no defects, there's a small chance that you'll find a bug or something that hasn't been documented as well as it could be. If that happens, we'd really value your feedback, which you can send by submitting an issue to Matcha on Github.